Using Denoising Diffusion Model for Predicting Global Style tokens in an Expressive Test-to-Speech System
Text-to-speech (TTS) systems based on neural networks have undergone a significant evolution, taking a step forward towards achieving human-like quality and expressiveness, which is crucial for applications such as social media content creation and voice interfaces for visually impaired individuals. An entire branch of research, known as Expressive Text-to-speech (ETTS), has emerged to address the so-called one-to-many mapping problem, which limits the naturalness of generated output. However, most ETTS systems applying explicit style modeling treat the prediction of prosodic features as a regressive, rather than generative, process and, consequently, do not capture prosodic diversity. We address this problem by proposing a novel technique for inference-time prediction of speaking-style features, which leverages a diffusion framework for sampling from a learned space of Global Style Tokens-based embeddings, which are then used to condition a neural TTS model. By incorporating the diffusion model, we can leverage its powerful modeling capabilities to learn the distribution of possible stylistic features and, during inference, sample them non-deterministically, which makes the generated speech more human-like by alleviating prosodic monotony across multiple sentences. Our system blends a regressive predictor with a diffusion-based generator to enable smooth control over the diversity of generated speech. Through quantitative and qualitative (human-centered) experiments, we demonstrated that our system generates expressive human speech with non-deterministic high-level prosodic features.
Method
The backbone of the system is a modified version of the FastSpeech acoustic model, aimed at predicting mel-spectrogram from one-hot encoded phonemes. The model uses explicit phoneme duration prediction to find mapping between spectrogram and phonemes dimensionality. During training, spectrogram generation is conditioned using style embedding, obtained from a GST module. The enriched phoneme representations, enhanced with BERT token-level embeddings and style embedding tokens are used as the ground-truth data to train GST Predictor, which aims to predict the style information solely from the textual input during inference. GST Predictor comprises of: 1) Deterministic predictor, which predicts the GST weights; 2) DDPM-based embedding predictor, which generates a non-deterministic embedding using a denoising framework. During inference, both embeddings are linearly combined using a hyperparameter lambda:
SE = lambda * SE_Det + (1 - lambda) * SE_NDet
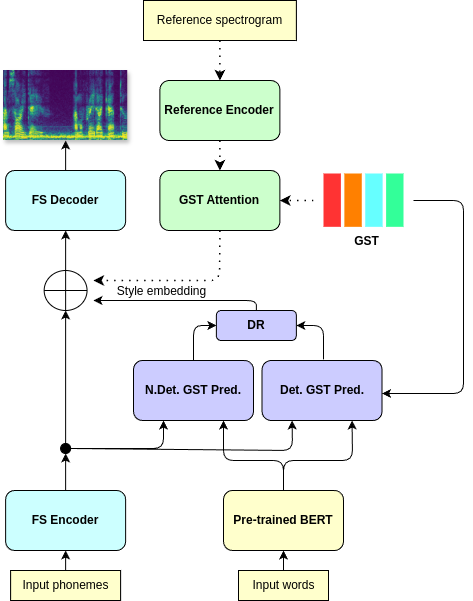
Figure: Overall architecture of the system.
Speech samples
We trained our model on the LJSpeech dataset. Then, we generated outputs for speech samples, unseen during training. We compare the generated speech with the Tacotron 2 baseline and the vanilla model without GST support. Then, we show how manipulating the lambda parameter influences the diversity of speech properties.
Models comparison
"The bread was issued every alternate day; and while some prisoners often ate their whole allowance at once,"
Ground truth
Tacotron 2
Vanilla
Proposed (lambda = 0.4)
"where they inevitably meet with further contamination from the society of the most abandoned and incorrigible inmates of the jail."
Ground truth
Tacotron 2
Vanilla
Proposed (lambda = 0.4)
"At the Italian Opera in the evening the audience, on the Queen's appearance, greeted her with loud cheers, and called for the national anthem."
Ground truth
Tacotron 2
Vanilla
Proposed (lambda = 0.4)
"with small groups of those truly representative of large employers of labor and of large groups of organized labor,"
Ground truth
Tacotron 2
Vanilla
Proposed (lambda = 0.4)
Speech diversity
lambda = 0.2
"they were followed by a crowd of reckless boys, who jeered at and insulted them."
1
2
3
4
lambda = 0.4
"they were followed by a crowd of reckless boys, who jeered at and insulted them."
1
2
3
4
lambda = 0.6
"they were followed by a crowd of reckless boys, who jeered at and insulted them."
1
2
3
4
lambda = 0.8
"they were followed by a crowd of reckless boys, who jeered at and insulted them."
1
2
3
4